想要查看内容赶紧注册登陆吧!
您需要 登录 才可以下载或查看,没有账号?立即注册
x
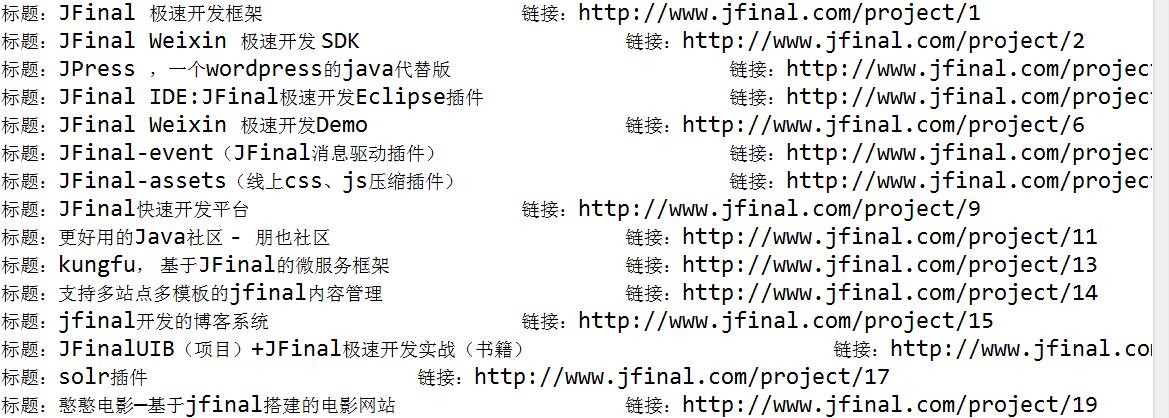
采用Java爬虫框架WebMagic,灵活,简单;
效果: java代码:(所用到的jar包在源码里面)
public class SpiderTest implements PageProcessor {
private Site page = Site.me().setRetryTimes(3).setSleepTime(1000);
/* 启动蜘蛛 */
public static void main(String[] args) {
Spider.create(new SpiderTest()).addUrl("http://www.jfinal.com/project").thread(5).run();
}
@Override
public Site getSite() {
return page;
}
@Override
public void process(Page page) {
/* 获取html源码 */
Html html = page.getHtml();
/* 使用xpath获得标题和链接 */
List hrefs = html.xpath("//div[@class='jf-panel-item']/h3/a/@href").all();
Listtitles = html.xpath("//div[@class='jf-panel-item']/h3/a/text()").all();
for (int i = 0; i < titles.size(); i++) {
System.out.println("标题:" + titles.get(i) + "\t\t\t链接:" + hrefs.get(i));
}
}
}
| 



 |Archiver|手机版|小黑屋|我爱代码 - 专业游戏安全与逆向论坛
( 陇ICP备17000105号-1 )
|Archiver|手机版|小黑屋|我爱代码 - 专业游戏安全与逆向论坛
( 陇ICP备17000105号-1 )





 发表于 2017-6-13 12:03:55
发表于 2017-6-13 12:03:55